
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 강화학습프로젝트
- ros2 docker
- AI올림픽
- sensor fusion
- Ros
- docker
- AI Olympics 러닝
- Humble
- ubuntu
- AI olympic
- s24
- 갤럭시s24
- PPO알고리즘
- 센서퓨전
- message_filters
- foxy
- cuDNN
- ROS2
- AI Olympics 레슬링
- 자율주행카메라
- 메시지필터
- lidar-camera
- 블랙플라이
- ubuntu22.04
- 자율주행
- AMZ
- 강화학습
- 센서데이터
- IJCAI-ECAI
- blackfly
- Today
- Total
나름 공부하는 일상
AI Olympic 레슬링, 러닝 도전기 #0 본문
지난(2023) 학기 Term Project의 일환으로 진행했던 PPO 알고리즘을 활용한 에이전트 학습 과정을 공유하려고 한다.
0. Team "윤성빈"의 한 학기 동안의 여정
앞으로 4~5개 포스팅을 통해 지난 한 학기 동안 우디(?) 친구랑 밤을 새우며 학습시켰던 우리 레슬링, 러닝 에이전트를 소개하려고 한다. 먼저 본격적인 시작에 앞서 최종 학습 결과를 공유하고자 한다.
Wrestling(레슬링)
레슬링의 경우, 초반 레슬링 규칙에 대해 파란색 공, 빨간색 공, 둘 다 몰라 랜덤으로 행동했기에 학습하기가 상대적으로 어려웠다. 이를 해결하기 위해 먼저 상대편을 정지시킨 상태로 파란색 공(나)에게 레슬링 규칙을 학습시켰고, 이후 파란색 공이 학습한 레슬링 규칙을 상대편에도 적용시켜 서로 대결을 할 수 있도록 하였다.
[학습 순서-요약]
1. 한 색상에 대해 레슬링 규칙 학습
2. 학습된 레슬링 규칙을 두 선수(공)에게 이식
3. 서로 경기를 진행하며 추가 학습
최종적으로 랜덤으로 어떤 선수(공)를 선택하든 같은 행동을 할 수 있도록 코드를 수정하였다.
다음은 레슬링 최종 결과이다.
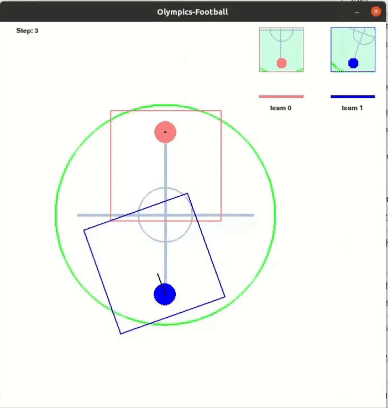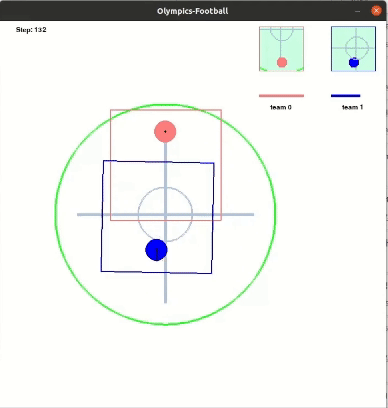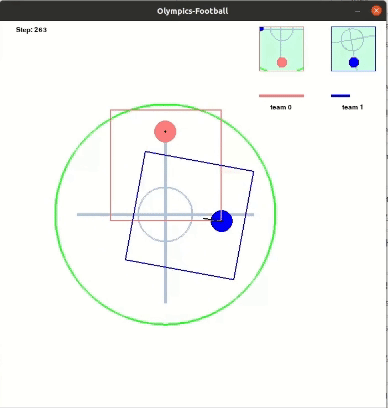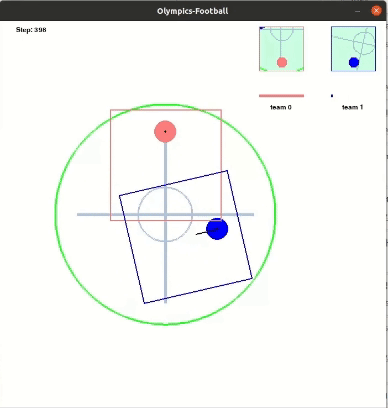

Running(달리기)
러닝의 경우, 레슬링에 비해 쉽게 학습을 시킬 수 있었는데 대신 빠르게 들어오게 하는데에 많은 어려움이 있었다.
선수(공)들은 바닥에 그려진 화살표 방향을 기준으로 어느 방향으로 이동할지 학습시켰고, 3번 T자 맵에서 좌우 구분이 어려웠던 문제가 있었다. 자세한 학습 방법과 어떤 실수가 있었는지는 이후 포스팅에 작성하려 한다.
[학습 순서-요약]
1. 화살표를 기준으로 달리기 규칙 학습
2. 학습된 달리기 규칙을 두 선수(공)에게 이식
3. 서로 경기를 진행하며 추가 학습
다음은 러닝 최종 결과이다.




본격적인 학습 도전기
https://narmstudy.tistory.com/9
AI Olympic 레슬링, 러닝 도전기 #1
지난(2023) 학기 Term Project의 일환으로 진행했던 PPO 알고리즘을 활용한 에이전트 학습 과정을 공유하려고 한다. 1. 강화학습, 첫 만남 이번에도 어떤 강의를 수강할지 이름으로 정한 나는 "인공지
narmstudy.tistory.com
'IT 개발 > 강화학습 PPO' 카테고리의 다른 글
| AI Olympic 레슬링, 러닝 도전기 #2 (0) | 2024.01.29 |
|---|---|
| AI Olympic 레슬링, 러닝 도전기 #1 (2) | 2024.01.29 |

